



GraphQL tem se destacado como uma solução flexível para APIs, oferecendo aos desenvolvedores a capacidade de realizar consultas precisas e eficientes, eliminando a necessidade de overfetching ou underfetching de dados. No entanto, mesmo com sua eficiência intrínseca, a otimização de consultas e a implementação de cache em GraphQL são essenciais para melhorar a performance e a escalabilidade das aplicações. Este artigo explora algumas técnicas avançadas para otimizar consultas GraphQL e como utilizar cache de forma eficaz.
Por Que Otimizar Consultas em GraphQL?
Embora GraphQL ofereça flexibilidade e poder ao desenvolvedor ao permitir consultas específicas, sem otimização adequada, grandes volumes de dados e consultas complexas podem sobrecarregar o servidor e degradar o desempenho da aplicação. O principal objetivo da otimização em GraphQL é reduzir a carga no backend e garantir respostas rápidas, mesmo quando as consultas são extensas ou quando os dados precisam ser agregados de várias fontes.
Evite Overfetching e Underfetching
Uma das maiores vantagens de GraphQL é evitar o overfetching e underfetching, dois problemas comuns em APIs REST tradicionais. No entanto, isso exige uma gestão cuidadosa das consultas.
Overfetching ocorre quando a consulta retorna mais dados do que o necessário, o que pode acontecer se o cliente não estiver controlando bem os campos solicitados. Para evitar isso, as consultas devem ser sempre revisadas e ajustadas de acordo com a necessidade exata da aplicação.
Underfetching, por outro lado, é quando a consulta não recupera dados suficientes, levando a múltiplas requisições. A solução é garantir que a consulta seja bem estruturada, fornecendo todos os dados relevantes de uma vez.
Implementação de Paginação e Limite de Dados
Para grandes volumes de dados, a paginação é uma técnica crucial de otimização. Em vez de carregar todos os registros de uma vez, a paginação permite que os dados sejam carregados em blocos menores, reduzindo a carga no servidor e melhorando o tempo de resposta.
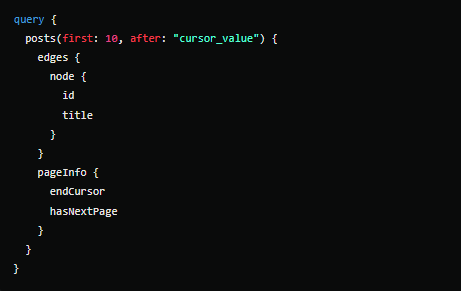
GraphQL suporta dois tipos principais de paginação:
- Offset-based Pagination: A paginação baseada em offsets utiliza um número de registro inicial e um limite de quantos registros carregar.
- Cursor-based Pagination: A paginação baseada em cursores é mais eficiente para sistemas distribuídos e grandes conjuntos de dados, pois evita problemas de inconsistência e ordenação.
Batching e DataLoader
Batching é uma técnica poderosa em GraphQL para otimizar a execução de consultas que precisam buscar dados relacionados. O DataLoader, uma biblioteca popular para GraphQL, permite agrupar várias consultas em uma única chamada de banco de dados, reduzindo o número de requisições e melhorando a eficiência.
Por exemplo, ao invés de realizar uma requisição ao banco de dados para cada objeto individualmente, o DataLoader pode agrupar várias requisições em uma única chamada, retornando todos os dados de uma vez.

Neste exemplo, as requisições para o usuário com ID 1 e ID 2 são agrupadas em uma única chamada ao banco de dados.
Cache em GraphQL
Cache é uma das formas mais eficazes de melhorar o desempenho de consultas GraphQL, especialmente em sistemas que lidam com grandes volumes de dados ou onde a latência da rede é uma preocupação. Existem diferentes níveis de cache que podem ser implementados em GraphQL:
- Cache no Cliente: Ferramentas como Apollo Client e Relay oferecem suporte nativo ao cache, armazenando os resultados das consultas no navegador. Isso permite que as respostas sejam reutilizadas sem precisar fazer uma nova requisição ao servidor.
- Cache no Servidor: Implementar cache no servidor é uma técnica mais complexa, mas extremamente eficaz para evitar consultas desnecessárias ao banco de dados. Ferramentas como Redis são frequentemente usadas para esse propósito.
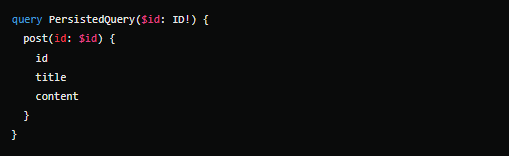
- Persisted Queries: Uma técnica onde as consultas são armazenadas no servidor e o cliente apenas envia um identificador em vez da consulta completa. Isso não só reduz a quantidade de dados trafegados, mas também melhora a segurança ao evitar a execução de consultas dinâmicas.
Cache com Apollo Server
O Apollo Server é uma das bibliotecas mais utilizadas para criar servidores GraphQL em Node.js, e ele oferece suporte nativo ao cache. Utilizando directives e cache hints, você pode configurar o comportamento de cache diretamente nas resoluções das consultas.
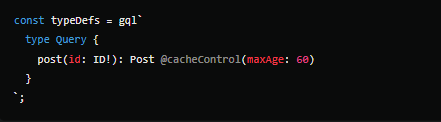
Neste exemplo, o resultado da consulta post será armazenado em cache por 60 segundos. Dependendo da complexidade dos dados e da necessidade de atualizações, esse tempo pode ser ajustado.
Conclusão
A otimização de consultas e o uso de cache em GraphQL são essenciais para garantir que suas aplicações continuem rápidas e responsivas à medida que escalam. A implementação de técnicas como paginação, batching com DataLoader, e cache no cliente e servidor pode melhorar significativamente o desempenho de suas APIs GraphQL.
Para facilitar ainda mais o desenvolvimento e integração de APIs poderosas, considere utilizar soluções como o APIBrasil, que oferece uma vasta gama de APIs otimizadas e seguras para elevar suas aplicações ao próximo nível.
![]()






