No desenvolvimento de aplicações distribuídas, a necessidade de gerenciar grandes volumes de dados em tempo real é uma constante. O Apache Kafka, uma plataforma de mensagens distribuídas, tem se destacado como uma solução poderosa para construir sistemas que exigem alta escalabilidade, durabilidade e desempenho em tempo real. Neste artigo, exploraremos como o Apache Kafka pode ser utilizado para desenvolver aplicações distribuídas e as principais considerações para implementá-lo.
O que é Apache Kafka?
Apache Kafka é uma plataforma de streaming distribuída que permite publicar, assinar, armazenar e processar fluxos de registros em tempo real. Criado originalmente pelo LinkedIn e depois open-sourced, Kafka foi projetado para lidar com streams de dados em grandes volumes de forma eficiente.
Arquitetura Básica
Kafka funciona com uma arquitetura baseada em produtores, consumidores, tópicos e brokers:
- Produtores: Aplicações que publicam mensagens em um ou mais tópicos no Kafka.
- Consumidores: Aplicações que assinam tópicos e consomem mensagens.
- Tópicos: Canais de transmissão onde as mensagens são categorizadas e armazenadas.
- Brokers: Servidores que fazem parte do cluster Kafka e gerenciam o armazenamento das mensagens nos tópicos.
Casos de Uso Comuns para Apache Kafka
Kafka é altamente versátil e pode ser utilizado em diversos cenários onde a transmissão e o processamento de dados em tempo real são críticos.
Processamento de Dados em Tempo Real
Uma das aplicações mais comuns do Kafka é o processamento de dados em tempo real. Empresas que necessitam processar grandes volumes de logs, métricas, eventos de usuário e dados de sensores utilizam Kafka para transmitir dados a partir de diferentes fontes, processá-los e armazená-los em bancos de dados ou outras plataformas de análise.
Integração de Microserviços
Em arquiteturas de microserviços, Kafka pode atuar como o backbone de comunicação entre serviços. Ele facilita a troca de mensagens assíncronas entre microserviços, permitindo que as aplicações sejam mais desacopladas e resilientes. Por exemplo, um microserviço de pedidos pode publicar eventos de novos pedidos em um tópico Kafka, e outros microserviços, como de faturamento ou estoque, podem consumir esses eventos para realizar suas respectivas tarefas.
Monitoramento e Análise de Logs
Kafka é amplamente utilizado para centralizar logs de sistemas distribuídos. Em vez de cada serviço gravar seus próprios logs de forma isolada, os logs podem ser enviados para Kafka, onde são agregados e analisados em tempo real.
Configurando e Utilizando Kafka em Aplicações Distribuídas
Setup do Cluster Kafka
Para configurar um ambiente Kafka, é necessário ter pelo menos um servidor (broker), mas em produção, geralmente se utiliza um cluster de brokers para garantir alta disponibilidade e escalabilidade. Além disso, é comum empregar o ZooKeeper para gerenciar o cluster Kafka.
Produção e Consumo de Mensagens
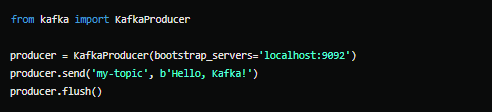
Produzir e consumir mensagens no Kafka pode ser feito utilizando APIs em várias linguagens, como Java, Python, e Go. Abaixo, um exemplo simples de um produtor em Python:
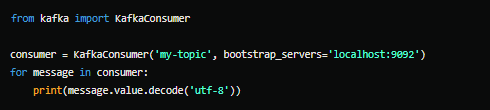
E um consumidor:
Escalabilidade e Manutenção
Uma das grandes vantagens do Kafka é sua capacidade de escalar horizontalmente. Ao adicionar mais brokers ao cluster, o Kafka distribui a carga de trabalho entre eles, permitindo que grandes volumes de dados sejam processados de forma eficiente. É essencial monitorar o desempenho do cluster Kafka e ajustar configurações como o número de partições dos tópicos para otimizar o throughput.
Desafios e Considerações
Embora Kafka ofereça inúmeras vantagens, há desafios a serem considerados:
- Gerenciamento de Estado: Em sistemas distribuídos, o gerenciamento do estado pode ser complexo. Kafka Streams é uma API poderosa que ajuda a gerenciar o estado de maneira eficaz, mas exige um entendimento profundo.
- Latência: Em algumas situações, a latência pode ser uma preocupação. É importante ajustar as configurações de replicação e sincronia para balancear entre consistência e latência.
- Monitoramento e Logging: Configurar uma solução robusta de monitoramento é crucial para garantir a operação suave de um cluster Kafka, especialmente em ambientes de produção.
Conclusão
O Apache Kafka é uma ferramenta poderosa para o desenvolvimento de aplicações distribuídas que necessitam de processamento em tempo real, alta disponibilidade e escalabilidade. Seja em arquiteturas de microserviços, processamento de grandes volumes de dados ou integração de sistemas, Kafka oferece uma base sólida para a construção de sistemas modernos e resilientes.
Se você está buscando aprimorar ainda mais suas aplicações distribuídas, considere explorar as APIs oferecidas pelo APIBrasil, que podem fornecer dados e funcionalidades que elevam a performance de seus sistemas Kafka.
![]()