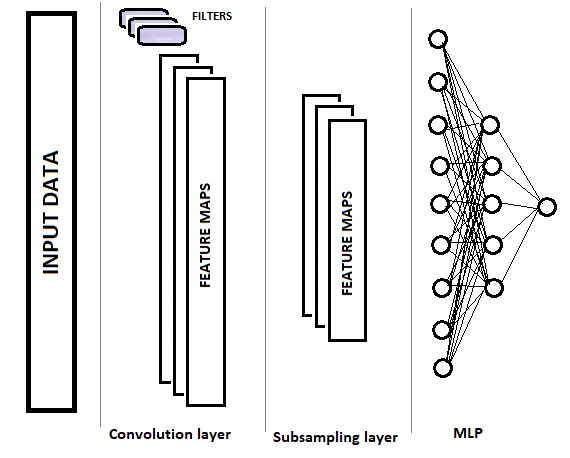
As redes neurais convolucionais (CNNs) revolucionaram o campo do aprendizado de máquina, especialmente no reconhecimento de imagens e visão computacional. Assim, projetadas para aprender padrões espaciais e hierárquicos em dados visuais, essas redes oferecem resultados altamente precisos em tarefas como classificação de imagens, detecção de objetos e segmentação semântica.
Portanto, neste artigo, você vai entender a fundo a arquitetura, funcionamento e aplicações práticas das CNNs.
O Que São Redes Neurais Convolucionais?
Redes neurais convolucionais são um tipo especializado de rede neural projetada para processar dados com estrutura de grade, como imagens. Ou seja, inspiradas no funcionamento do córtex visual humano, as CNNs detectam automaticamente padrões como bordas, texturas e formas ao longo de diferentes camadas.
Componentes Fundamentais das CNNs
1. Camada Convolucional (Convolutional Layer)
Executa a operação de convolução entre um filtro (kernel) e a imagem de entrada. Portanto, o objetivo é extrair características locais, como contornos ou texturas.
2. Função de Ativação (ReLU)
Aplica uma função não linear (tipicamente ReLU) para aumentar a complexidade dos padrões aprendidos pela rede.
3. Camada de Pooling
Reduz dimensionalidade e complexidade computacional. A mais comum é a max pooling, que seleciona o valor máximo em regiões específicas.
4. Camadas Totalmente Conectadas (Fully Connected)
Após várias camadas convolucionais e de pooling, os dados são achatados e passados para uma ou mais camadas densas para realizar a classificação final.
5. Função de Perda e Backpropagation
A rede calcula a perda (geralmente com cross-entropy) e ajusta os pesos por meio do backpropagation com otimização (ex.: Adam, SGD).
Exemplo de Arquitetura Típica de CNN
textCopiarEditarInput (64x64x3)
→ Conv (3x3, 32 filtros) + ReLU
→ Max Pooling (2x2)
→ Conv (3x3, 64 filtros) + ReLU
→ Max Pooling (2x2)
→ Flatten
→ Dense (128 unidades) + ReLU
→ Dense (10 unidades) + Softmax
Aplicações Práticas
- Classificação de Imagens: Reconhecimento facial, identificação de doenças em exames médicos.
- Detecção de Objetos: Localização de múltiplos objetos em imagens (YOLO, SSD).
- Segmentação de Imagens: Separação de objetos em uma imagem (ex.: U-Net).
- Reconhecimento de Escrita Manual: Leitura de dígitos (MNIST) e textos manuscritos.
Boas Práticas
- Data Augmentation: Aumenta a diversidade dos dados de treino para evitar overfitting.
- Regularização (Dropout, L2): Previne que a rede memorize os dados.
- Normalização de Imagens: Escala os pixels para uma faixa comum (ex.: 0 a 1).
Conclusão
As redes neurais convolucionais são a base de diversas aplicações modernas em IA e visão computacional. Ou seja, sua capacidade de extrair características visuais com precisão torna essas redes indispensáveis em projetos de classificação, detecção e análise de imagens.
Portanto, quer enriquecer seus modelos com dados confiáveis e atualizados? Então explore as APIs do APIBrasil e potencialize seu projeto de machine learning com informações de alta qualidade, prontas para integração. Aplique inteligência com eficiência, precisão e escala.
![]()









